
My last couple of blogs have focused on Master Data Management and the options that an architect has. I have been contacted by a reader who wanted me to go deeper into the hub patterns I mentioned.

There are a number of architectural approaches and patterns to provision a quality single version of the truth with respect to key business entities and reference entities.
The most common is frequently referred to as a hub pattern due to its central focus of access, but not necessarily the same system of entry (SoE).
Invariably, the use of more than one hub patterns is the most likely course of action, either to address different requirements, or as part of a transition program. These hub patterns require an initial load of data to lay a solid foundation of quality data. Afterward, the capabilities of the hub keep the data synchronized.
Virtual Hub (aka Registry Hub)
One of the most common is known as the Virtual Hub pattern also known as the Registry Hub Pattern. A virtual hub leaves the authoritative data in the source systems and uses data virtualization techniques to dynamically assemble a master record in real-time.
This virtualization approach requires the virtual hub to store a master index of unique identifiers which map to source system key references to assist in the retrieval of the master record. In addition to the unique identifiers and source system key references, the virtual hub will store entity-identifying attributes to assist with search requests from information consumers without having to go the source systems after every search request. The number of identifying attributes is variable depending on identification requirements.
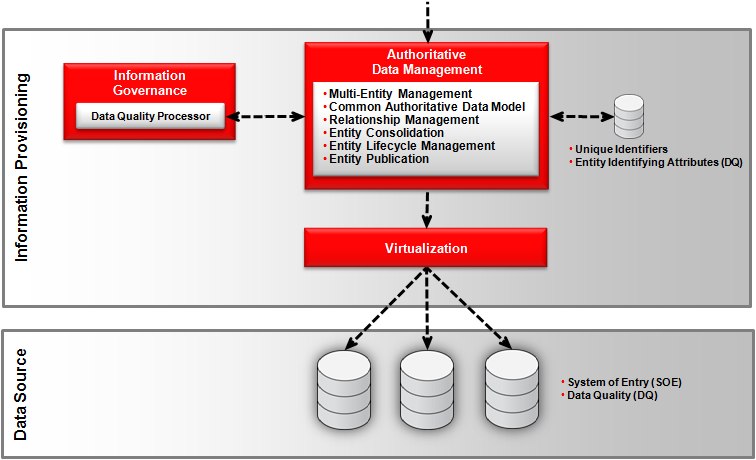
Each source system remains in control of its own data (SOE – System of Entry) and there is a reliance on data quality (DQ) being applied by the source systems. But the identifying attributes held within the hub should be cleansed. Due to the complexity and capabilities of the source systems, a virtual hub tends to be read-only where the survivorship rules are applied at data access.
While this hub pattern might seem ideal due to having no impact on existing applications to be updated, it does have a heavy reliance on the source systems for both performance and reliability.
Centralized Hub (aka Transaction Hub)
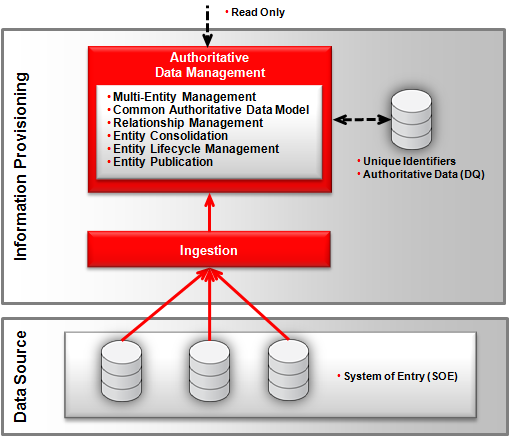
The Centralized Hub pattern also known as the Transaction Hub Pattern stores all authoritative data for an entity and also is the system of entry (SOE). The centralized hub can be seen as the opposite of a virtual hub where the data and system of entry are de-centralized. The centralized hub stores all authoritative data, unique identifiers and any new attributes which are not found in the underlying operational systems.

This hub manages all entity lifecycle operations (Create, Update, etc.) and interacts with a data quality processor to make sure that data has been cleansed. The centralized hub is a read/write system and has a large impact on applications that need to be updated so that any changes to authoritative data are made through the hub as the operational systems are not the system of entry anymore. This, in effect, makes this hub the ‘System of Record’ (SOR).
If required, updates to the authoritative data in the centralized hub can be published and propagated to subscribing systems via data ingestion techniques such as bulk data movement and incremental data movement.
Consolidated Hub
A consolidated hub aggregates authoritative data from source systems using ingestion techniques and stores it within a master data store in the consolidated hub. This consolidated approach requires the storage of unique identifiers and of quality authoritative data. Each source system remains in control of its own data (SOE) but the consolidation technique ensures that both data quality processes and survivorship rules are applied to the authoritative data at the time of consolidation.
Like the virtual hub, the consolidated hub is read-only and has no impact on existing applications to be updated. The consolidated hub is less reliant on the source system than the virtual hub as performance and reliability of the source systems are hidden to some extent due to the data being available for consumption from within the consolidation hub. But due to the consolidated nature of this hub, the data within the hub can become stale due to the latency between consolidations.
Hybrid Hub (aka CO-Existence Hub)
A hybrid hub, as indicated by the name, is a combination of the capabilities of a virtual hub, consolidated hub and centralized hub. Authoritative data are stored in both the hub and in the source systems. The hybrid hub is commonly used as a transition architecture when moving from a virtual hub to a centralized hub.
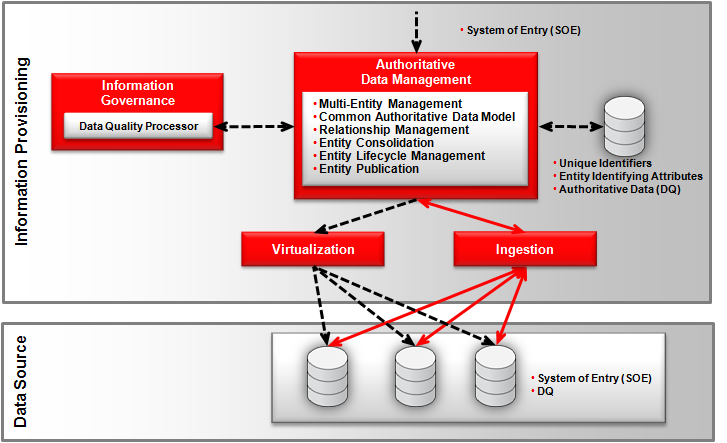
During this transition there will invariably be a mixture of applications that utilize the hub as the primary source of authoritative data and applications that do not. Applications that do not use the hub as their primary source of authoritative data are still the system of entry for their specific systems. The hub can also be a system of entry where changes to the authoritative data can be propagated to subscribing applications. This hybrid approach leads to an increased level of complexity over a virtual hub due to the synchronization that is required between the hub and the source systems, which may highlight a number of discrepancies and conflicts that will have to be managed.
Another approach to employing a hybrid hub is more in line with the virtual hub but attempts to address the performance issues related to virtualization techniques. As with the virtual hub, the hybrid hub contains unique identifiers and mapped source system key references. It also contains the consolidated authoritative data from the source systems of the most common or the most important attributes. This allows the hybrid hub to respond to information consumer requests by using authoritative data stored in the hub. When it cannot be satisfied by replicated data alone, then the hybrid hub utilizes the same virtualization approach described in the virtual hub. As with any form of replication there is data latency which will lead to the hybrid hub containing stale data.
The hybrid hub is responsible for applying data quality processes to the replicated data and management of entity-identifying attributes. But it also relies on the source systems to cleanse its data when virtualization access is utilized.
Both performance and reliability are dependent on the source systems when utilizing virtualization access.
Good Luck, Now Go Architect…
