
In my last blog I highlighted various techniques to acquire data. One of these was Data Ingestion. I thought I would cover this in more detail.
Latency
The need and timeliness of data should be taken into account when deciding which
ingestion mechanism to employ.
This comes down to the degree of latency that is acceptable for a user from the data being ingestion from the source system to the target systems.
- Batch – Unfortunately this is still the most common approach that enterprises rely on, whereby data is ingested on a regular interval, e.g. monthly, weekly, daily
- Micro-Batch – This approach ingests the delta of the data since the last data ingestion. Data is ingested on a more frequent basis then in a batch mode, e.g. every 5 minutes.
- Trickle-Feed – This approach ingests data as soon as it becomes available. Data is continuously being ingested
Topology
There are a number of ingestion topologies that are commonly employed to address organization’s ingestion requirements.
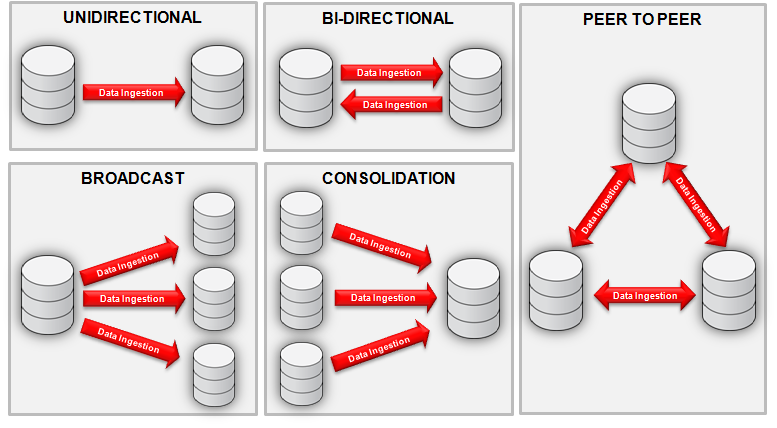
- Unidirectional – Ingests data from one source data store to a target data store. Example uses cases include offloading reporting requests from production systems and live standby for fail-over purposes.
- Broadcast – Similar to unidirectional pattern but used for ingestion of data to several target data stores. An example use case includes data distribution to several databases which can be utilized for different and distinct purposes, i.e. reporting, test environment, etc.
- Bi-Directional – Ingests changed data bidirectionally between two data stores to keep both sets of data stores current. Example use case includes an active-active instant fail-over.
- Peer to Peer – Similar to the bi-directional pattern but data is kept current in multiple databases forming a multi-master configuration. Example use cases include load balancing as load is shared between the databases equally, and high availability as additional databases will still be available if one database fails.
- Consolidation – Ingests data from several source data stores to a single target data store for the purposes of data consolidation.

While this is not an exhaustive list of ingestion topologies these foundational ingestion topologies enable an architect to define additional more complex topologies by combining two or more topologies together. For example a cascading ingestion topology can be obtained by combining the consolidation and unidirectional ingestion topologies.
Communication Style
The communication style employed when ingesting data from a source data store can be characterized as either a push or pull technique. The push technique is reliant on the source data store to initiate the push of data when a change occurs.. Whereas, a pull technique relies on data being pulled from a source data store (this is generally less intrusive). The pull technique often requires a mechanism to identify what has changed since the last pull. In addition the pull technique may need to be scheduled at a time when impact on operational performance will not be a problem.
Other Consideration
The following is a sample list of architectural requirements that should be considered when deciding which ingestion topology, engines and patterns to utilize.
- Filtering Requirements
- High Availability Requirements
- Performance Requirements
- Transformation Requirements
- Security Requirements
- Data Quality Requirements
- Read-only Requirements
- Data Volumes and Retention Requirements (current and projected)
- Network Latency
- Data Ingestion Latency
- Data Variety
- Regulatory Requirements (e.g. ingestion is not permitted)
Good Luck, Now Go Architect…
