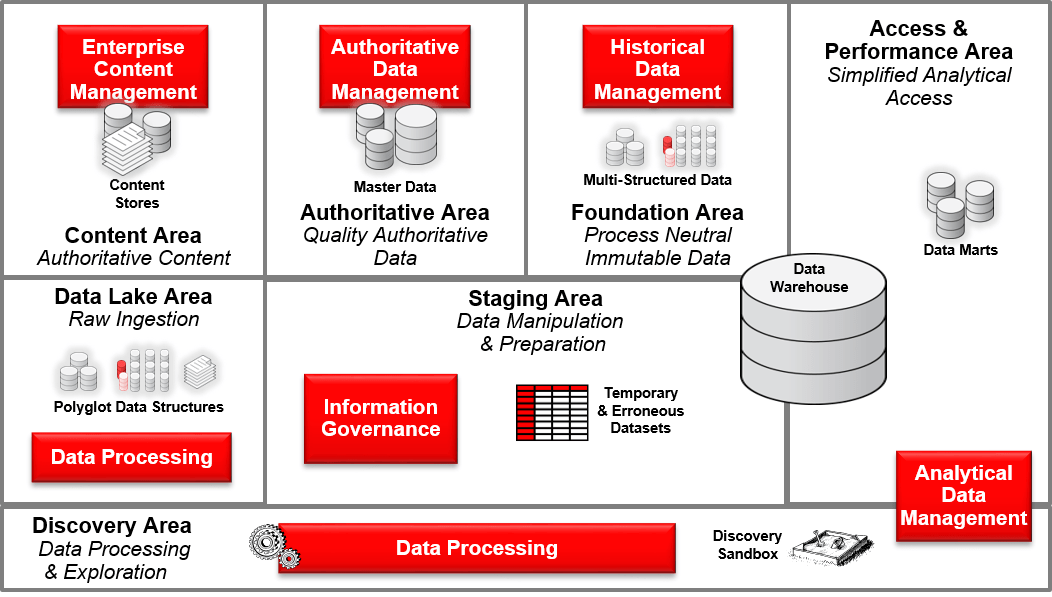
When I need to architect a data focused solution such as an Operational Data Store (ODS), a Master Data Management (MDM), or a Logical Data Warehouse (DW), I tend to rely on a notion called Areas of Responsibility. This notion should be seen as a logical construct and not physical representation on where and how data is stored.

These logical areas support and enable various information provisioning capabilities and support the separation of concerns around logically defined boundaries of responsibilities. These distinct areas not only have distinct capabilities but also have their own logical data stores to support their capabilities and the role they play in an overall information management approach.
Apart from the Data Lake Area, not all of the areas are required. The requirement of each area is driven by the final data solution you are attempting to architect.
Data Lake Area
The Data Lake Area acts as a permanent area where raw data ingestion and potential processing occurs for downstream usage and consumption. Generally, the Data Lake Area is the first destination of data that has been acquired. This provides a level of isolation between data that will be moved into an Information Provisioning layer and data that is generally available to consumers via a serving layer.
By providing this isolation, data can be acquired at various rates, (e.g. in small frequent increments or large bulk transfers), asynchronous to the rate at which data are refreshed for consumption. Data can be acquired through a variety of synchronous and asynchronous mechanisms. The mechanisms taken will vary depending on the data source capability, capacity, regulatory compliance, and access requirements.
While it is advantageous to have data ingested into the Data Lake Area in real-time this is not always possible and the effort required may not bear fruition.
So as a starting point I like to ingest data at the rate and frequency which can be justified and therefore driven by the business needs in support of the various information provisioning scenarios (e.g. Master Data Management (MDM), Big Data Processing, and Data Warehousing).
Staging Area
When there are requirements that dictate that data are clean, consistent, and complete (as far as is practical), the Staging Area is where data quality business rules are applied to achieve these objectives. The Staging Area can act as either a temporary and/or permanent area where data cleansing occurs for the production of quality data for downstream usage.
Generally this area acquires its raw data from the Data Lake Area,. In addition this area can contain many different type of data objects such as:
- Decode Tables – These tables hold the master list to coordinate integration of multiple sources.
- Lookup Tables – These tables are reference tables for codes.
- Erroneous Tables – These tables hold rejected data that has failed consistency and quality checks. Rejected data are retained in this area for manual or automatic correction.
- Temporary Tables – These tables are truncated and reused with every load
Foundation Area
The Foundation Area is responsible for managing uniformed data for the long term. In order to most easily adapt to changes in the organization over time, structured data are maintained here in a business neutral form.
Changes to organizational structures and business processes should not impact the way data are stored in this area. Versatility takes precedence over navigation and performance. For unstructured data, the Foundation Area is commonly used as a collection point of historical record.
Serving Area
The Serving Area is used to represent data in ways that best serve the
consumer of the data (e.g. analytical community). This area is free to represent data for most efficient access and ease of navigation.
The structure of the Serving Area is dependent upon the tools and
applications using the data. For structured data, this will often consist of dimensional models and/or cubes. In addition, it may contain aggregations of facts (rollups) for rapid query responses.
Serving Area structures can be instantiated and changed at will in order to conform to the business hierarchies of the day. For unstructured data, this area may be implemented as a subset of historical data with or without additional metadata, indexing, or relationships added that enhance
accessibility and query performance.
In addition, the deployment of specialized hardware or software can enable this layer with caching mechanisms and in-memory databases to meet query response time requirements.
Authoritative Area
The Authoritative Area is responsible for managing master and key reference entities such as Customer, Supplier, Account, Site, and Product. The data can be managed within the Authoritative Area either virtually, physically, or a combination of both of these methods.
The Authoritative Area maintains master cross-references for every master business object and every attached system. With all the master data in the Authoritative Area, only one ingestion point is needed into upstream or downstream systems that require the consumption and delivery of these key master and reference entities. This enables the Authoritative Area to support operational data by ensuring quality and providing consistent access for use by operational applications, while also supporting the delivery of consistent historical and analytical reporting.
Content Area
The Content Area is responsible for managing and providing access to user generated unstructured/semi-unstructured data.
While data in the Content Area is indexed and searchable, the true value of this data is when it is not just utilized in isolation but in conjunction with other forms of data such as operational data and authoritative data. Therefore the Content Area enables the consumption and access of user generated unstructured/semi-unstructured data to downstream systems.
Discovery Area
The Discovery Area provisions and manages a number of investigative data stores (aka Sandboxes) to enable exploratory analysis. The Discovery Area ingests data from various downstream and upstream sources in support of specific business problems. It is also where user-defined data can be introduced for simulation and forecasting purposes.
Within the Discovery Area the data can be used to discover new insights and relationships. Any discovered valuable results are then made available to be ingested into either downstream or upstream systems.
These sandboxes tend to be initiated and owned by data analysts/scientists and typically have a limited lifespan. This data is processed and analyzed using any and all tools at the disposal of the Data Scientist, and therefore can often be resource and processing intensive.
Anyway, in later blogs I will discuss various scenarios on which these areas of responsibilities can be utilized,
Good Luck, Now Go Architect…
